[Metric Learning] 거리(Distance)로 지능을 정의하다: Spectral부터 Deep Metric Learning까지
1. 서론: 분류(Classification)를 넘어 거리(Distance)의 공간으로
우리가 흔히 접하는 딥러닝 모델은 대부분 "이 사진은 고양이인가, 강아지인가?"를 맞히는 분류(Classification) 문제를 풉니다. 이때 사용하는 Softmax 함수는 정해진 클래스(Closed-set) 내에서 확률을 계산하는 데에는 탁월하지만, 치명적인 한계가 있습니다.
만약 학습 때 본 적 없는 새로운 강아지 품종이 들어오면 어떻게 될까요? 혹은 얼굴 인식 시스템(FaceID)에 등록되지 않은 외부인이 카메라를 본다면요? 일반적인 분류 모델은 이를 억지로 기존 클래스 중 하나로 끼워 맞추려 할 것입니다.
여기서 Metric Learning(메트릭 러닝)이 등장합니다. Metric Learning의 목표는 "이것은 무엇인가?"를 맞히는 것이 아니라, "이것과 저것은 얼마나 닮았는가?"를 수치화하는 것입니다.
즉, 데이터 간의 유사도(Similarity)를 거리(Distance)로 표현하는 함수를 학습하는 것입니다.
2. Metric Learning의 정의 (What is Metric Learning?)
학술적으로 Metric Learning은 데이터 간의 관계를 잘 표현하는 거리 함수(Distance Metric)를 학습하는 과정입니다.
- 직관적 정의: "유사한 데이터(Similar)끼리는 거리를 가깝게(Pull), 다른 데이터(Dissimilar)끼리는 거리를 멀게(Push) 만드는 임베딩 공간을 학습하는 것"
- 수학적 정의: 가장 기본이 되는 도구는 일반화된 마할라노비스 거리(Generalized Mahalanobis Distance)입니다.
$$d_W(x_i, x_j) = \sqrt{(x_i - x_j)^T W (x_i - x_j)}$$
여기서 학습 가능한 행렬 $W$가 $I$(단위행렬)라면 유클리드 거리와 같지만, Metric Learning은 데이터의 분포를 고려하여 최적의 $W$를 찾아냅니다.
- Deep Metric Learning: 최근에는 행렬 $W$ 대신, 딥러닝 신경망 $f(\cdot)$을 사용하여 데이터를 비선형 공간으로 매핑한 뒤 거리를 잰다는 점이 다릅니다.
$$D(x_i, x_j) = |f(x_i) - f(x_j)|^2$$
3. Metric Learning의 계보 (Taxonomy)
Metric Learning은 단순히 요즘 유행하는 기술이 아니라, 통계학과 기하학에 뿌리를 두고 발전해 왔습니다. 'Spectral, Probabilistic, and Deep Metric Learning: Tutorial and Survey (2022)' 논문에 따르면, Metric Learning은 크게 세 가지 접근 방식으로 나뉩니다.
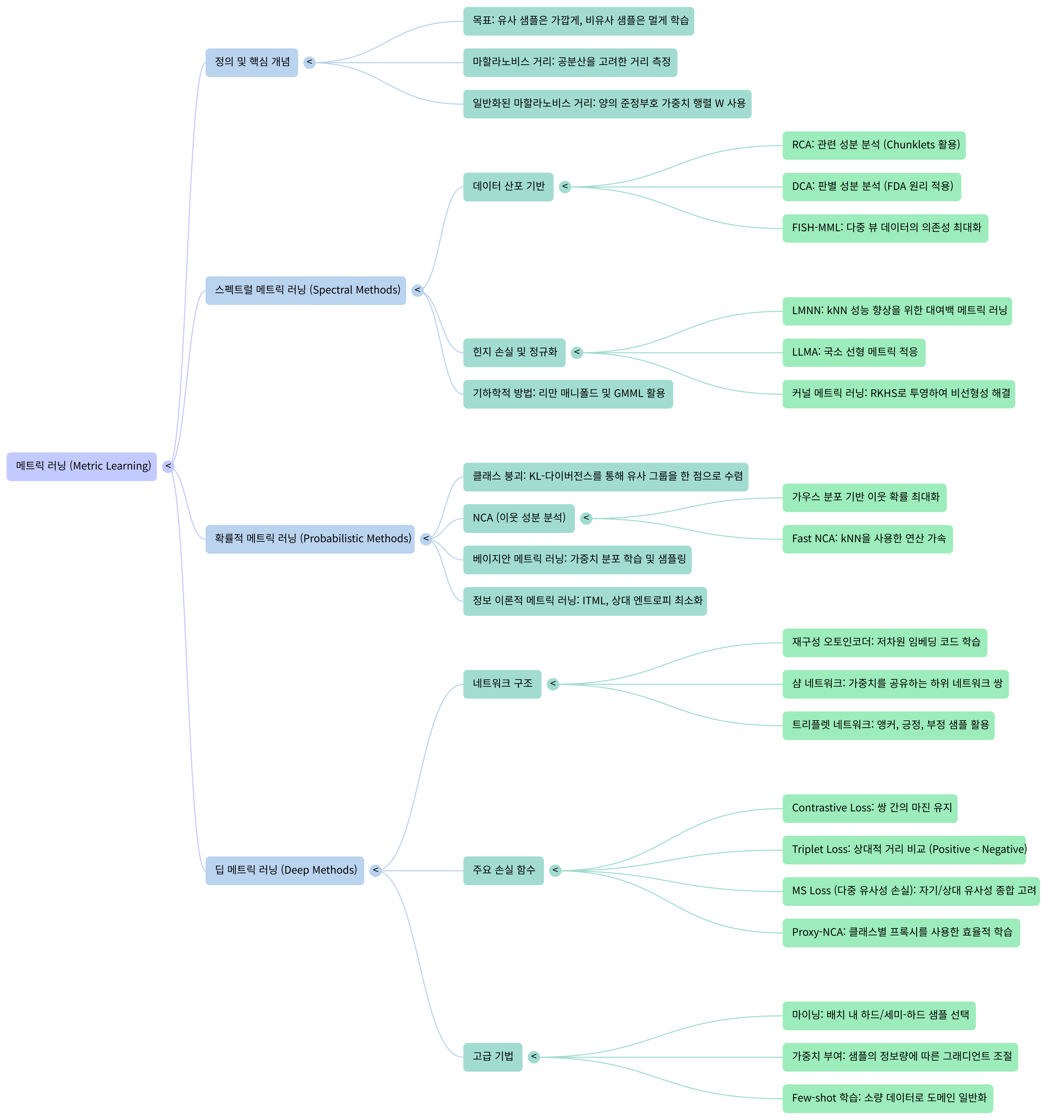
1) Spectral Metric Learning (스펙트럴 방식)
데이터의 분산(Scatter) 행렬과 고윳값 분해(Eigenvalue Decomposition)를 이용해 수학적으로 최적의 부분 공간을 찾습니다.
- 대표적으로 Fisher Discriminant Analysis (FDA)나 LMNN (Large Margin Nearest Neighbor)이 있으며, "클래스 내 분산은 줄이고, 클래스 간 분산은 키우는" 방향으로 행렬 $W$를 학습합니다.
2) Probabilistic Metric Learning (확률적 방식)
데이터 포인트가 서로를 이웃으로 선택할 확률(Probability)을 모델링합니다. 거리가 가까울수록 이웃으로 선택될 확률($p_{ij}$) 이 높다는 가정을 사용합니다.
- 대표적으로 NCA (Neighborhood Component Analysis)가 있으며, 이는 딥러닝 시대에 Proxy-NCA 등으로 계승되어 발전했습니다.
3) Deep Metric Learning (딥러닝 방식)
선형 변환($W$)의 한계를 넘어, 신경망(Neural Network)을 이용해 데이터를 비선형 공간으로 매핑합니다.
- Pair-based Loss: Contrastive Loss, Triplet Loss, MS Loss 등 데이터 쌍(Pair) 간의 거리를 직접 조절합니다.
- Proxy-based Loss: CosFace, ArcFace 등 대푯값(Proxy)이나 각도(Angle)를 이용해 임베딩 공간을 학습합니다.
4. 결론: 왜 지금 다시 Metric Learning인가?
결국 Metric Learning은 "데이터를 어떻게 표현(Representation)할 것인가?"에 대한 해답입니다. 단순히 정답을 맞히는 것을 넘어, 데이터가 가진 본질적인 관계를 기하학적 공간에 매핑하는 이 기술은 얼굴 인식, 이미지 검색, 추천 시스템 등 수많은 분야의 핵심이 되고 있습니다.